
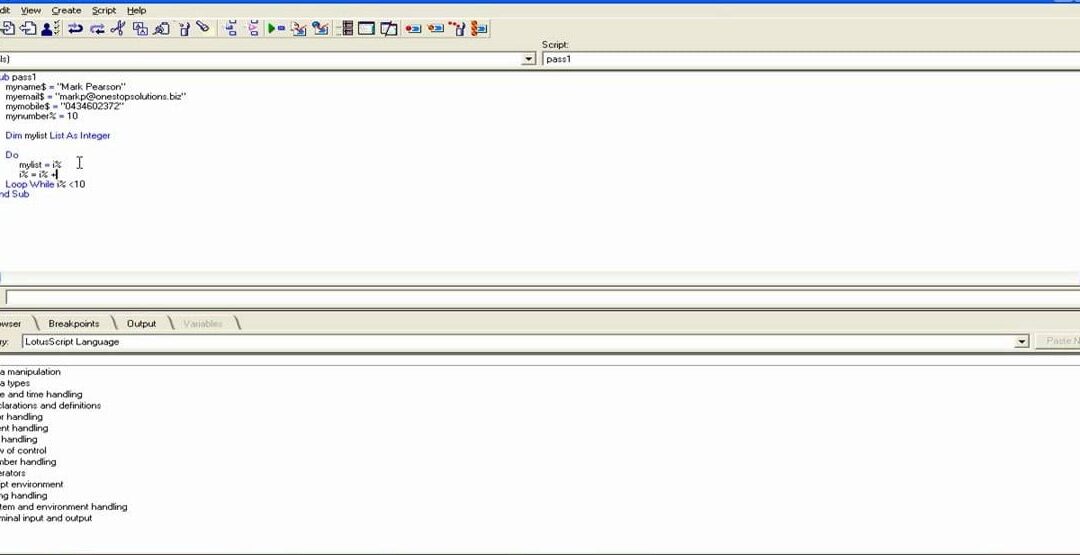
Hace unos días mostré un plugin de wordpress (más que nada es solo un Shortcode con administración de la caché generada) donde comenté que hacer un extractor del contenido relevante de una página de noticias es algo muy sencillito que solo necesita de un par de loops.
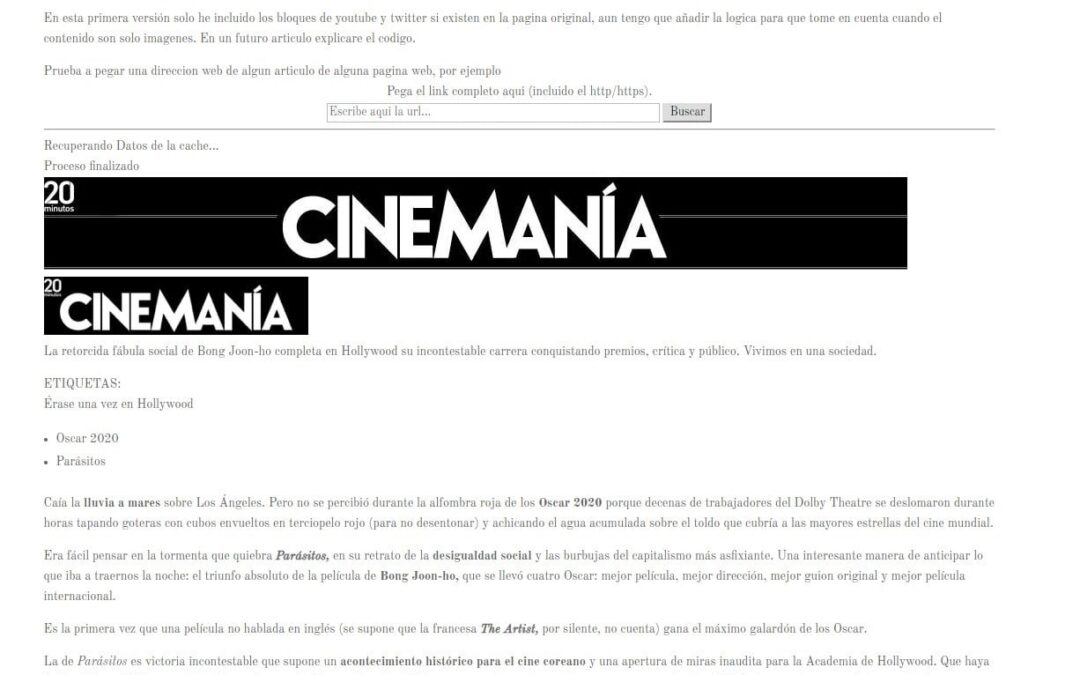
Y para qué quiero esto uno puede preguntarse. Para la extracción general de contenidos de noticias. Tienes todas tus páginas en un listado RSS y te gustaría se mostrase tu contenido en el lector de tu móvil para poder leerlo mientras viajas en el tren. Como indexador de contenidos de la web. Como generador automatico de posts en blogs.
Pues bien vamos allá, alehop!
$doc->loadHTMLFile($name)
$elements = $doc->getElementsByTagName('*');
foreach ($elements as $element) {
if ( ($element->nodeName == 'p') or ($element->nodeName == 'br')
or ($element->nodeName == 'h2') or ($element->nodeName == 'h3')
or ($element->nodeName == 'h4') or ($element->nodeName == 'b')
or ($element->nodeName == 'img') )
continue;
$work = $element->cloneNode(TRUE);
remove_children($work);
$len = ( $work->childNodes->length ) * strlen($element->textContent) ;
if ( $len > $olen){
$doc->formatOutput = TRUE;
$html .= $doc->saveHTML($element);
$olen = $len;
}
}
function remove_children(&$node) {
$childNodes = array();
foreach($node->childNodes as $childNode) {
if ( ($childNode->nodeName != 'p') and ($childNode->nodeName != 'br')
and ($childNode->nodeName != 'h3') and ($childNode->nodeName != 'h3')
and ($childNode->nodeName != 'h4') and ($childNode->nodeName != 'b')
and ($childNode->nodeName != 'img')
){
$childNodes[] = $childNode;
}
$old_node = $childNode->nodeName;
}
foreach ($childNodes as $childNode) {
$childNode->parentNode->removeChild($childNode);
}
unset($childNodes);
}Esta claro, ¿No? En cualquier caso me hace ilusión explicar cada bloque para que se vea que es lo que hace. Por supuesto el programa tiene mucho mas codigo que esto pero la parte que determina cual es el contenido relevante se puede resumir a estos dos ForEach.
$doc->loadHTMLFile($name)
$elements = $doc->getElementsByTagName('*');
foreach ($elements as $element) {
if ( ($element->nodeName == 'p') or ($element->nodeName == 'br')
or ($element->nodeName == 'h2') or ($element->nodeName == 'h3')
or ($element->nodeName == 'h4') or ($element->nodeName == 'b')
or ($element->nodeName == 'img') )
continue;
$work = $element->cloneNode(TRUE);
remove_children($work);Esta parte es muy sencilla, el programa básicamente recorre todas las etiquetas HTML de la página web. Para evitar trabajar con etiquetas de texto o imagenes ya que no queremos que nos calcule cada párrafo del texto ( para ahorrar tiempo de ejecución) ponemos las excepciones adecuadas.
Si encuentra una de esas etiquetas continua a la siguiente.
Después clona el nodo (con todas sus etiquetas hijas) ya que vamos a modificarlo en la siguiente instrucción.
function remove_children(&$node) {
$childNodes = array();
foreach($node->childNodes as $childNode) {
if ( ($childNode->nodeName != 'p') and ($childNode->nodeName != 'br')
and ($childNode->nodeName != 'h3') and ($childNode->nodeName != 'h3')
and ($childNode->nodeName != 'h4') and ($childNode->nodeName != 'b')
and ($childNode->nodeName != 'img')
){
$childNodes[] = $childNode;
}
$old_node = $childNode->nodeName;
}
foreach ($childNodes as $childNode) {
$childNode->parentNode->removeChild($childNode);
}
unset($childNodes);
}Esta parte es todavía más sencilla. Accedemos a los hijos directos del nodo y nos quedamos solo con los textos y las imágenes. Cualquier otra etiqueta HTML se guarda en un Array para ser borradas después del nodo padre. Esto hace que solo nos quedemos con la última etiqueta que contiene el texto relevante ya que las etiquetas anidadas seguiría con el proceso de drill-down (en el bucle que llama esta función) he ignorará cualquier caso tipo. Esto lo hago así para evitar que el DOMDocument se pierda cuando borra objetos, ya que si se borra directamente un nodo la función pierde la jerarquía del resto (en vez de borrar ese nodo y los hijos). Esto también permite recuperar varios bloques de texto seguidos en etiquetas DIV.
<div>
<div><div><p>texto</p></div></div> <!- Esta etiqueta no la tiene en cuenta.
<!- las siguientes dos etiquetas si las incluirá en el resultado.
<div><p>texto</p></div>
<div><p>texto</p></div>
</div>Y ya solo nos queda la parte más fácil de todas, calcular un valor para determinar si es el contenido que buscamos o no. Para eso lo calculamos usando la siguiente fórmula: (Cantidad de etiquetas presentes en el nodo) * (Longitud del texto plano).
Esto lo hago así porque nos aseguramos que el resultado que nos traemos contenga etiquetas de texto o imágenes. Si el nodo contiene un muro de texto pero no contiene ninguna o una cantidad muy baja de etiquetas que estamos buscando como por ejemplo un listado, el listado de los menús, los pies de página… No tendría el suficiente valor para ser incluido en el resultado.
$len = ( $work->childNodes->length ) * strlen($element->textContent) ;
if ( $len > $olen){
$doc->formatOutput = TRUE;
$html .= $doc->saveHTML($element);
$olen = $len;
}Y en base a eso hago una selección determinista del contenido, solo queremos bloques más grande de contenido cada vez para evitar traer anuncios o cualquier otro tipo de objeto. Esto evita duplicar bloques sin tener que hacer una comparativa de contenido.
Al final una captura avariciosa del contenido porque aunque puedo quedarme solo con el bloque con el mejor valor de esta forma se trae también otros bloques que pudieran ser obviados debido a que no son tan valiosos como los anteriores.
Por supuesto después de determinar el contenido hace otras operaciones como quitar el <head>, <footer>, <scripts>, limpiar las etiquetas de <img> para limpiar las librerías LazyLoad… Para mostrar un contenido más limpio. Pero eso mejor lo dejo para otro momento porque ya entramos en el apasionante mundo del REGEX…


0 comentarios